Forskare: ”Se upp med komplexa coronamodeller – de kan överträffa verkligheten”
DEBATT. Flera datamodeller som har presenterats för att förutse smittspridning av covid-19 har varit väldigt komplexa – trots brist på validerat underlag. Det bör man vara varsam med, skriver 15 forskare.
Vi ser gärna en öppen diskussion om styrkor och svagheter med den här typen av komplexa modeller.
Matematiska modeller är rent generellt kraftfulla verktyg i många discipliner. Ett exempel är den snabba utvecklingen av djupa neuronnät med miljontals parametrar, som tränade och validerade med miljontals väl valda datapunkter kan lösa mycket komplexa problem.
Simuleringsmodellen i rapporten av de sex svenska forskarna (Gardner m fl.) är komplex i den bemärkelse att den har många parametrar som är svåra att sätta. Vidare är de använda parametervärdena inte ett resultat av träning och validering på ett stort och representativt dataunderlag.
Annons
Supplementet till artikeln räknar upp 96 parametrar, många med tre decimalers noggrannhet, och i huvudartikeln modelleras olika samhällsinsatser med 19 olika procenttal.
Sammantaget har modellen således över 100 parametrar. Dessa parametrar är satta manuellt, företrädesvis utan tydligt motiverat stöd från empiriska studier.
• Texten ska vara max 4 000 tecken inklusive mellanslag.
• Undvik förkortningar och utropstecken.
• Peka ut och beskriv ett problem eller en lösning, samt hur du eller ni vill lösa problemet eller ta vara på möjligheten.
• Var tydlig med vem du eller ni debatterar med och varför.
• Bifoga gärna porträttbild och ange fotobyline.
Exempel: skolstängning eliminerar förstås risken för smittspridning i skolan men ökar enligt modellen samtidigt risken i samhället med 25 procent och i familjen med 50 procent för varje elev.
Totaleffekten beror på hur man modellerar smittspridning i varje miljö. Antar man att elever smittar lite eller inte alls i skolan, så blir nettoeffekten att smittspridningen kan öka efter en skolstängning.
Antar man samma smittspridning som i familj och fritid, så minskar smittspridningen signifikant.
Beroende på intrikata modellantaganden kan effekten av en skolstängning således antingen bli en ökning eller en minskning av reproduktionstalet, Re(t), som representerar hur många individer en infekterad individ i genomsnitt överför smittan till. Det kan också påverka hur smittan sprids mellan olika åldersgrupper, såsom till äldre. Är det mormor och morfar som passar barnen, eller föräldrarna som vabbar?
Resultaten i Gardners och Fergusons rapporter tyder på att modellerna predikterar att skolstängning minskar spridningen. En konsekvens av modellens inbyggda antaganden är att Sverige, som inte har stängt (alla) skolor, kommer sämre ut än andra i övrigt jämförbara länder.
I den svenska rapporten (Gardner m.fl.) modelleras varje individ, och varje individ befinner sig i ett av ett antal möjliga tillstånd (smittbar, smittad, immun...) och platser (hemma, på jobbet, i affären...).
Modellen har således många miljoner tillstånd, och författarna har använt flera superdatorer för att köra sina simuleringar.
Annons
Hur bra är då dessa komplexa modeller på att förutspå verkligheten? Låt oss först jämföra med betydligt enklare modeller, för att sedan ta en titt på utfallet efter att artikeln skrevs, då vi nu har en dryg veckas facit att jämföra med.
Exempel: Man kan återskapa principutseenden av de i den svenska rapporten publicerade figurerna med den allra enklaste och cirka 100 år gamla SIR-modellen.
SIR står för Susceptible Infected Removed och syftar på de tillstånd en individ kan befinna sig i enligt modellen. Läsaren kan själv implementera följande rekursion i valfritt programmeringsspråk:
SIR-modellen.
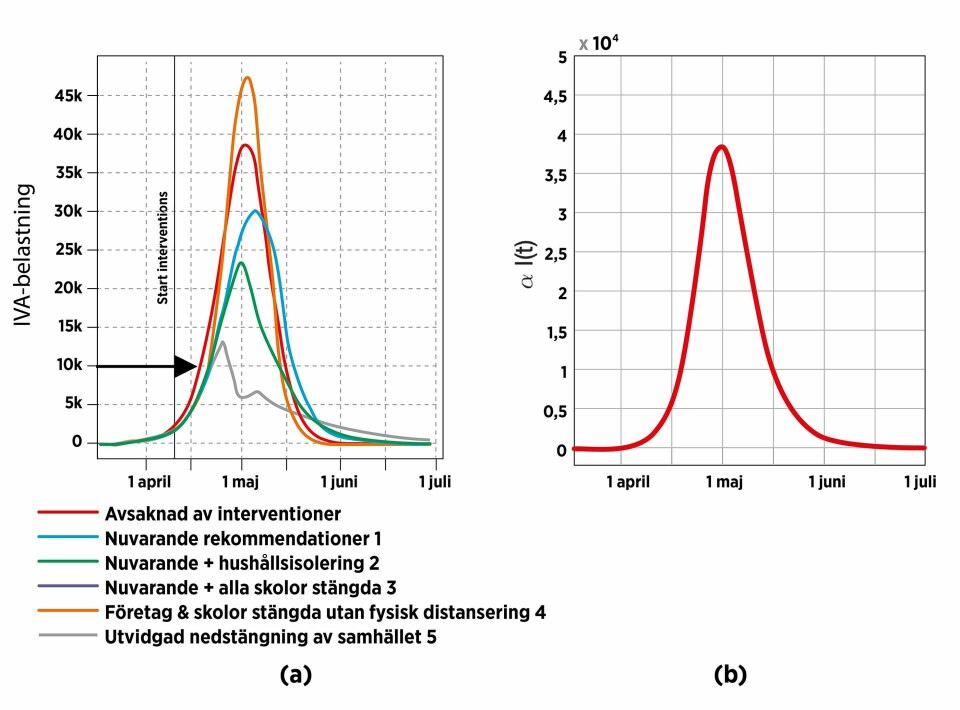
Koden ovan tar bråkdelen av en sekund att exekvera på en vanlig dator och den resulterande variationen av antal pågående infektioner över tid finns återgivet i Figur 1b, multiplicerat med en skalfaktor α som relaterar antalet infekterade till antalet i behov av intensivvård.
Det är svårt att se skillnaden i form på denna kurva och den röda kurvan i Figur 1a som återger predikterat behov av intensivvårdsplatser enligt Gardner m.fl.
Det krävs således inte superdatorer för att få fram figurerna i rapporten. För den betraktade figuren räcker det att veta dubbleringstakten och den ovan nämnda skalfaktorn.
Övriga figurer i artikeln kan återskapas på motsvarande vis med lämpliga antaganden om dödlighet och förändring i dubbleringstakt till följd av statliga interventioner.
Gardner m.fl. utvärderar även sin modell för en dubbleringstakt på fem dagar. Detta motsvarar i koden för den enkla modellen ovan att 1/3 ersätts med 1/5. Exemplet visar att det i princip endast är valet av två parametrar som styr kurvans huvudsakliga utseende och en som skalar till rätt nivå. Resterande hundratalet parametrar i den komplexa modellen bidrar endast till mindre formförändringar.
Figur 1. (a) Modellen från Gardner m.fl. predikterar ett behov av ca 10 000 IVA-platser 21 april (pilen), att jämföra med det faktiska behovet på drygt 500 platser. (b) Tillståndet I(t) erhållet genom enkel SIR-simulering och skalat med den i texten omnämnda faktorn, i detta exempel α=0.012, att jämföra med formen på den röda kurvan i (a). Ursprungsfiguren är hämtad från medRxiv, preprint doi https://doi.org/10.1101/2020.04.11.20062133. Den modifierade figuren är publicerad i enlighet med orginalverkets licens (CC-BY-NC-ND 4.0).
Den svenska rapporten offentliggjordes på medRxiv 14 april. Tidpunkten är intressant, då den sammanfaller med när effekterna av åtgärderna som regeringen införde 14 mars kan förväntas synas i rapporterade dödsfall.
Det finns flera veckors fördröjning mellan en intervention, till exempel uppmaning om social distansering, och dess eventuella inverkan på dödsfallsstatistiken. Denna fördröjning är såklart problematisk och en stark anledning till att skapa prediktionsmodeller.
Rapportens modell förutspår att i storleksordningen 100 000 svenskar kommer att avlida innan sommaren med gällande svensk strategi. Det predikterade behovet av IVA-platser uppgår som mest till 20 000–30 000, det vill säga 40 gånger fler än det initialt tillgängliga antalet, som var drygt 500 platser (Efter omprioriteringar i sjukvården finns nu en bit över 1 000.)
Nu med tio dagars facit att tillgå, visar sig verkligheten ligga långt ifrån modellens prediktion. Per den 21 april förutspådde modellen ett behov av ca 10 000 IVA-platser, medan den verkliga beläggningen var nästan en faktor 20 lägre.
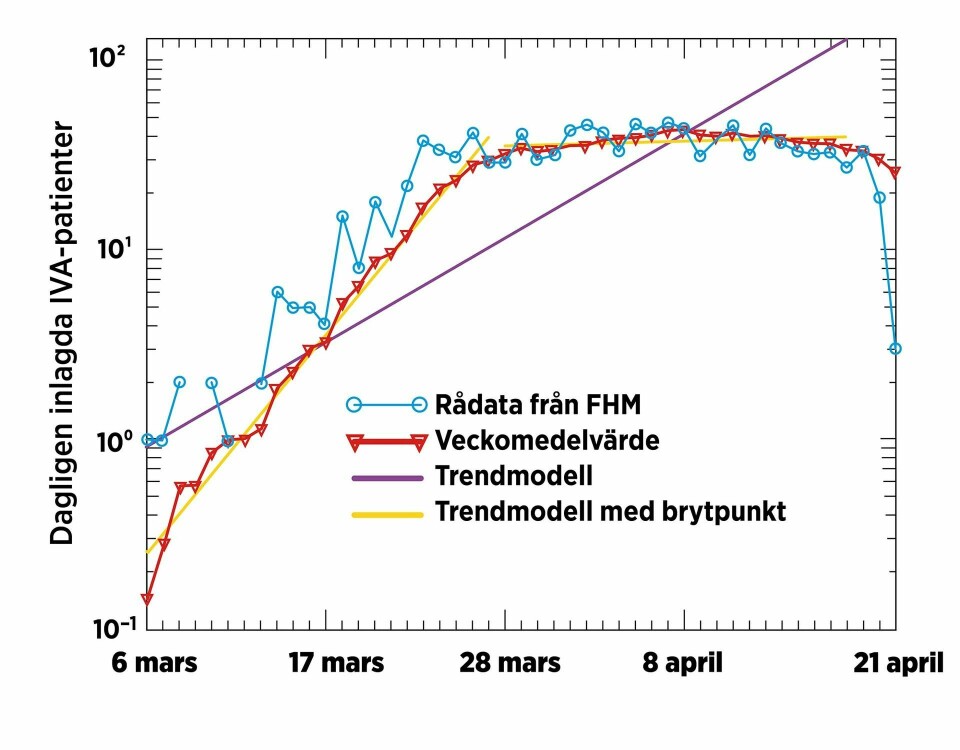
Figur 2 återger rådata från Folkhälsomyndigheten (FHM, se referenslista), tillgängliga per den 21 april. Figur 2 visar antalet personer som skrivits in på IVA en given dag (blå cirklar) och samma data veckovis medelvärdesbildat (röda trianglar).
Den dykande trenden i slutet av dataserien kan förklaras av den eftersläpning som finns i rapporteringen och bortses från i vår analys.
Antas reproduktionstalet Re(t) vara konstant, så bör även IVA-beläggningen växa (eller avta) exponentiellt.
Den lila trendlinjen, framtagen genom en minstakvadrat-anpassning, motsvarar detta antagande. Tillåts i stället Re(t) kunna variera, är det utifrån data rimligt att anta att brytpunkten kring 26 mars föranletts av en minskning av Re(t).
Beaktas denna brytpunkt i minstakvadrat-anpassningen, resulterar det i de gula trendlinjerna, som passar datan nämnvärt mycket bättre.
Figur 2. Antal dagligen nyinlagda på IVA. Trendmodellerna är anpassade med minstakvadratmetoden. Den lila visar en konstant exponentiell tillväxt (oförändratRet)), medan den gula har en brytpunkt som skulle kunna tolkas som effekten av regeringens nya rekommendationer i mitten på mars.
För att en komplex modell ska ha prediktiv förmåga krävs det att dess parametervärden valts utifrån tillförlitlig och tillräckligt informativ träningsdata. För att minska risken för överanpassning till träningsdata krävs det därtill separata valideringsdata som modellen kan utvärderas mot innan den tas i bruk.
Allmänt, men framförallt i en situation då adekvat tränings- och valideringsdata ej finns att tillgå, är den enklaste modell som beskriver tillgänglig data att föredra. Denna princip går under namnet Occams rakkniv, och är uppkallad efter franciskanermunken William Occam (f. 1285).
Enkla modeller är dessutom i regel mer transparenta i termer av hur parameterval relaterar till utfall, vilket även resulterar i att de ofta kan användas till att förklara fenomen, till skillnad från att endast generera ett utfall. Behoven av data-understödda parameterval och validering kvarstår dock även för enkla modeller.
För att summera: Modeller med högre komplexitet än vad tränings- och valideringsdata påbjuder bör användas sparsamt som beslutsunderlag.
I krisen testas vår krisberedskap, att vår demokrati står pall, att våra logistik-kedjor fungerar och att vård och omsorg får de resurser och den uppskattning de förtjänar. Likaså vill vi med denna artikel framhäva vikten av att vi vidhåller god vetenskaplig metodik.
Ofta behövs samarbete mellan individer som tillsammans har erforderlig spetskompetens för att implementera och simulera modeller respektive göra väl grundade parameterval, vilket belyser vikten av tvärdisciplinära samarbeten.
Då mängden parametrar och antaganden i en modell växer, växer även kravet på att validera dessa antaganden. Parametervärden valideras lämpligast mot data; antaganden prövas genom sedvanlig vetenskaplig granskning inför publicering.
När matematiska modeller används för att fatta samhällsviktiga beslut är detta krav kanske som allra störst.
Fredrik Gustafsson, professor i sensorinformatik, Linköpings universitet
Toomas Timpka, professor i socialmedicin och docent i medicinsk informatik, Linköpings universitet, överläkare vid folkhälso- och statistikenheten, Region Östergötland
Torbjörn Lundh, professor i biomatematik, Chalmers tekniska högskola och Göteborgs universitet
Armin Spreco, doktor i medicinsk vetenskap, Linköpings universitet, statistiker vid folkhälso- och statistikenheten, Region Östergötland
Kristian Soltesz, docent i reglerteknik, Lunds universitet
Joakim Ekberg, hälso- och sjukvårdsstrateg med inriktning eHälsa, doktor i medicinsk vetenskap vid Hälso- och sjukvårdsenheten, regionledningskontoret, Region Östergötland
Philip Gerlee, docent i biomatematik, Chalmers tekniska högskola och Göteborgs universitet
Örjan Dahlström, docent i psykologi, filosofie doktor i handikappvetenskap, civilingenjör, institutionen för beteendevetenskap och lärande, Linköpings universitet.
Fredrik Bagge Carlson, doktor i reglerteknik, National University of Singapore
Claes Andersson, docent i komplexa system, Chalmers tekniska högskola
Anna Jöud, docent i epidemiologi, Lunds universitet, epidemiolog vid avdelning forskning och utbildning, Skånes universitetssjukhus, Region Skåne
Joakim Jaldén, professor i signalbehandling, KTH
Ingemar Petersson, professor i ortopedi med inriktning försäkringsmedicin och sjukdomars konsekvenser, forskningschef, Skånes universitetssjukvård
Thomas B. Schön, professor i reglerteknik, Uppsala universitet
Bo Bernhardsson, professor i reglerteknik med forskningsinriktning mot osäkra system, Lunds universitet